
BeagleTA
BeagleTA: A Text Analysis Processing Pipeline for the analysis of relationships between documents based on word usage
Oliver Bonham-Carter, Web
email: obonhamcarter@allegheny.edu
Date: 9th April 2025
Github: BeagleTA
![]()
Overview
This project is a text analysis processing pipeline designed to analyze relationships between documents based on word usage. The pipeline consists of three main components: a parser, a CSV cleaner/filter, and a random sampler. Each component is implemented as a separate binary in Rust, allowing for efficient data processing and analysis.
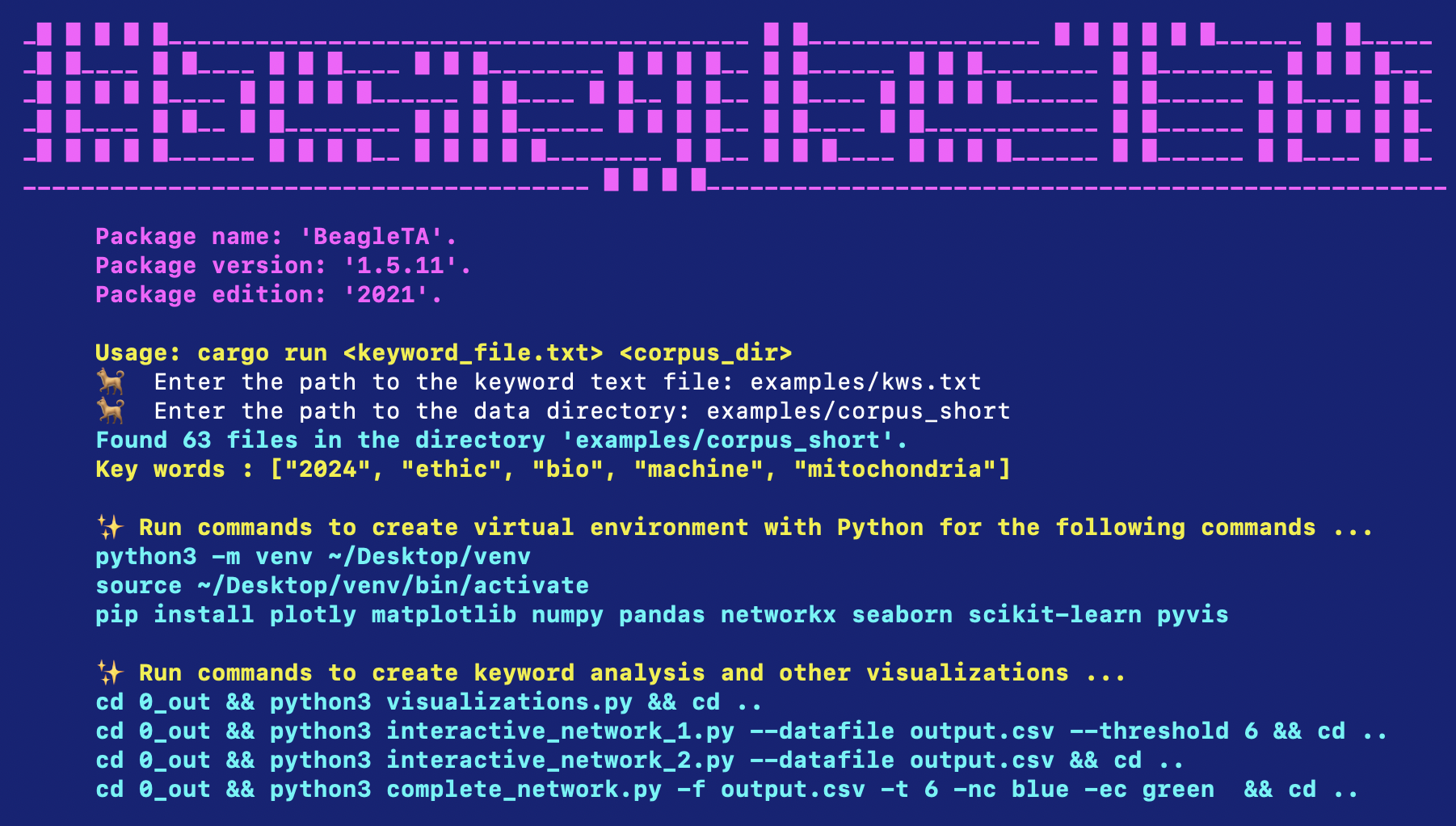
To simplify the maintenance of the code, the project was designed to be modular, allowing users to easily complete each task of a text analysis in three stages: parsing, cleaning, and sampling. There are three bins in the project and each is responsible for a specific task. We note that each task may be executed independently or in sequence to complete an analysis and get results. The modular design also allows for easy customization, enabling users to add new features or modify existing ones without affecting the entire pipeline.
The parser reads a list of keywords from a file and processes a directory of text files, extracting relevant data based on the keywords. The output is saved in a CSV file, which can then be cleaned and filtered using the CSV cleaner/filter binary. This binary removes unnecessary columns and rows based on user-defined parameters, resulting in a cleaned CSV file.
The random sampler binary randomly selects rows from the cleaned CSV file and generates one or more smaller CSV files. This is particularly useful for working with large datasets that are difficult to process or visualize in their entirety.
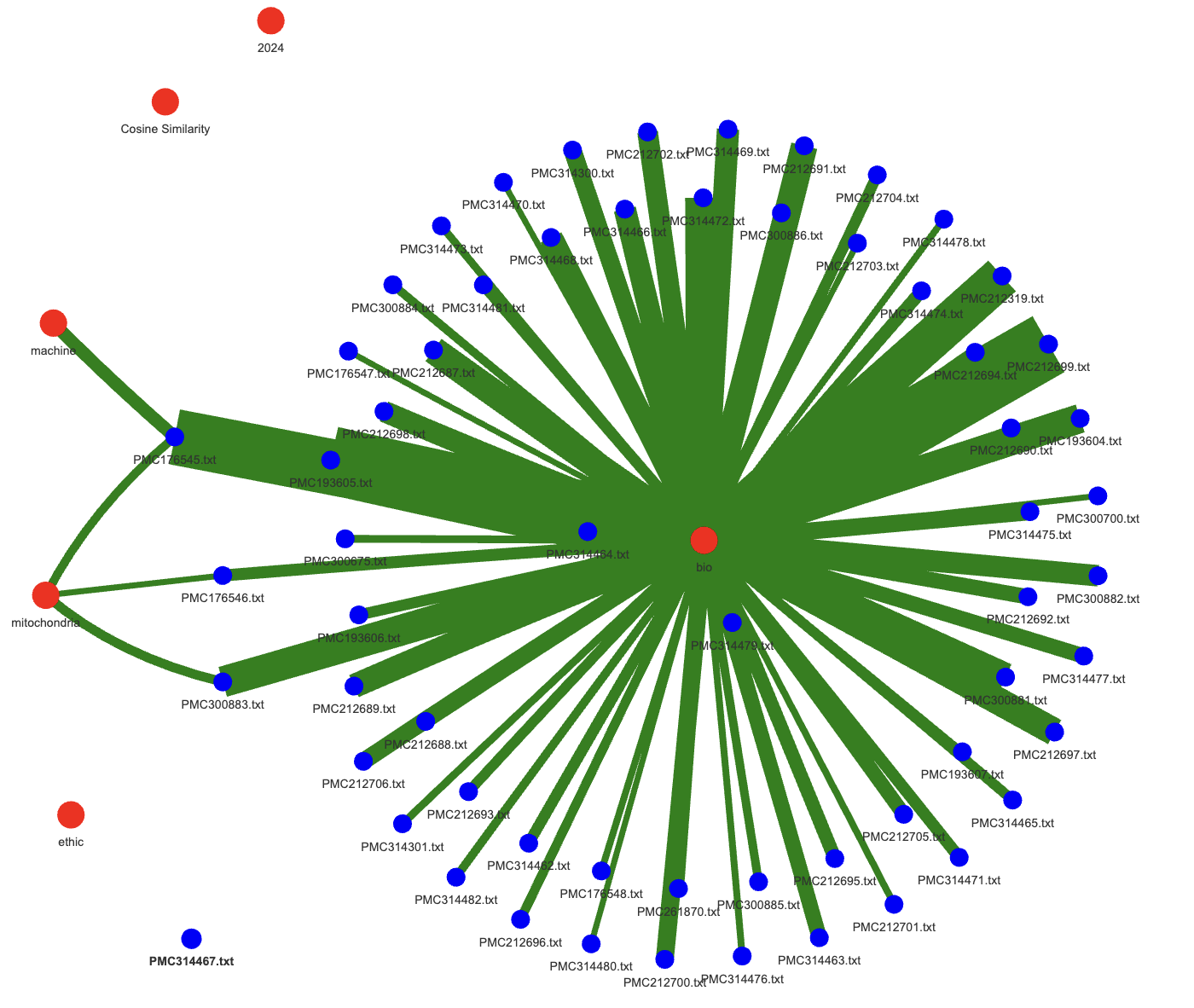
The pipeline is designed to be user-friendly, with clear usage instructions and examples provided for each binary. The command-line interface allows users to easily specify input and output files, as well as any additional parameters required for each task. This makes it easy to integrate the pipeline into existing workflows or to use it as a standalone tool for text analysis.
The pipeline is particularly useful for researchers and data scientists working with text data, as it provides a streamlined approach to processing and analyzing large datasets. The use of Rust for implementation ensures high performance and reliability, making it suitable for handling large-scale text analysis tasks.